多线程编程
Android沿用的是java的线程模型。
线程基础
进程与线程
线程是最小的执行单元,而进程由至少一个线程组成。如何调度进程和线程,完全由操作系统决定,程序自己不能决定什么时候执行,执行多长时间。
为何要使用多线程编程
- 减少程序响应时间
- 与进程相比,线程创建和切换开销更小,多线程在数据共享方面效率非常高
- 多核计算机本身就具备执行多线程的能力
- 简化程序结构,使程序便于理解和维护
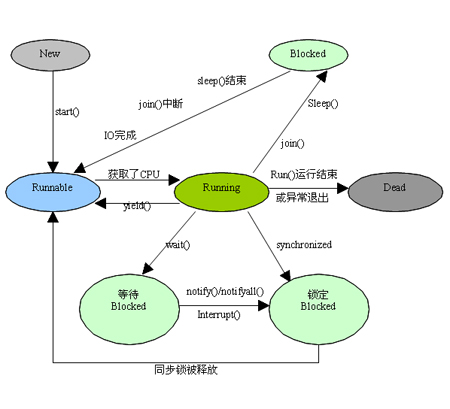
线程的状态
- New 新创建状态。新创建了一个线程对象,但还没有调用start()方法。
- Runnable 可运行状态。Java线程中将就绪(ready)和运行中(running)两种状态笼统的称为“运行”。线程对象创建后,其他线程(比如main线程)调用了该对象的start()方法。该状态的线程位于可运行线程池中,等待被线程调度选中,获取CPU的使用权,此时处于就绪状态(ready)。就绪状态的线程在获得CPU时间片后变为运行中状态(running)。
- Blocked 阻塞状态。表示线程阻塞于锁。 阻塞的情况分三种:
- 等待阻塞:运行的线程执行wait()方法,JVM会把该线程放入等待池中。
- 同步阻塞:运行的线程在获取对象的同步锁时,若该同步锁被别的线程占用,则JVM会把该线程放入锁池中。
-
其他阻塞:运行的线程执行sleep()或join()方法,或者发出了I/O请求时,JVM会把该线程置为阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。
- Waiting 等待状态。进入该状态的线程需要等待其他线程做出一些特定动作(通知或中断)。
- Timed waiting 超时等待状态。该状态不同于WAITING,它可以在指定的时间后自行返回。
- Terminated 终止状态。表示该线程已经执行完毕。
创建线程
1.继承Thread类,重写run()方法 2.实现Runnable接口,并实现该接口的run()方法 3.实现Callable接口,重写call()方法
一般推荐使用方法2,因为一个类应该在其需要加强或修改时才会被继承。因此如果没有必要重写Thread类的其它方法,最好使用Runnable接口方式。
理解中断
当线程的 run()方法执行方法体中的最后一条语句后,并经由执行 return语句返回时,或者出现在方法中没有捕获的异常时线程将终止。在java早期版本中有一个 stop方法,其他线程可以调用它终止线程,但是这个方法现在已经被弃用了。
interrupt方法可以用来请求终止线程,当一个线程调用 interrupt方法时,线程的中断状态将被置位。这是每个线程都具有的boolean标志,每个线程都应该不时的检查这个标志,来判断线程是否被中断。 要想弄清线程是否被置位,可以调用Thread.currentThread().isInterrupted()
如果一个线程被阻塞,就无法检测中断状态。这是产生InterruptedException的地方。当一个被阻塞的线程(调用sleep或者wait)上调用interrupt方法。阻塞调用将会被InterruptedException中断。
如果不知道抛出InterruptedException异常后如何处理,有两种合理的选择: 1.在catch中调用Thread.currentThread().interrup()来设置中断状态。调用者可以对其进行检测
void myTask(){
try{
sleep(50)
}catch(InterruptedException e){
Thread.currentThread().interrupted
}
}
2.更好的选择用throw InterruptedException标记你的方法,不采用try语句块来捕获异常。这样调用者可以捕获这个异常:
void myTask()throw InterruptedException{
sleep(50)
}
安全地终止线程
同步
在多线程的应用中,两个或者两个以上的线程需要共享对同一个数据的存取。如果两个线程存取相同的对象,并且每一个线程都调用了修改该对象的方法,这种情况通常成为竞争条件。
重入锁
ReentrantLock 是JAVA SE 5.0引入的, 用ReentrantLock保护代码块的结构如下:
mLock.lock();
try{
...
}
finally{
mLock.unlock();
这一结构确保任何时刻只有一个线程进入临界区,一旦一个线程封锁了锁对象,其他任何线程都无法通过lock语句。当其他线程调用lock时,它们则被阻塞直到第一个线程释放锁对象。把解锁的操作放在finally中是十分必要的,如果在临界区发生了异常,锁是必须要释放的,否则其他线程将会永远阻塞。
条件对象
要使用一个条件对象来管理那些已经获得了一个锁但是却不能做有用工作的线程,条件对象又称作条件变量。
一个锁对象拥有多个相关的条件对象,可以用newCondition方法获得一个条件对象,我们得到条件对象后调用await方法,当前线程就被阻塞了并放弃了锁
等待获得锁的线程和调用await方法的线程本质上是不同的,一旦一个线程调用的await方法,他就会进入该条件的等待集。当锁可用时,该线程不能马上解锁,相反他处于阻塞状态,直到另一个线程调用了同一个条件上的signalAll方法时为止。当另一个线程准备转账给我们此前的转账方时,只要调用condition.signalAll();该调用会重新激活因为这一条件而等待的所有线程。 当一个线程调用了await方法他没法重新激活自身,并寄希望于其他线程来调用signalAll方法来激活自身,如果没有其他线程来激活等待的线程,那么就会产生死锁现象,如果所有的其他线程都被阻塞,最后一个活动线程在解除其他线程阻塞状态前调用await,那么它也被阻塞,就没有任何线程可以解除其他线程的阻塞,程序就被挂起了。
当调用 signalAll方法时并不是立即激活一个等待线程,它仅仅解除了等待线程的阻塞,以便这些线程能够在当前线程退出同步方法后,通过竞争实现对对象的访问。还有一个方法是 signal,它则是随机解除某个线程的阻塞,如果该线程仍然不能运行,那么则再次被阻塞,如果没有其他线程再次调用 signal,那么系统就死锁了。
Synchronized关键字
synchronized 关键字是由JVM提供实现的。Lock 和 Condition 接口为程序设计人员提供了高度的锁定控制,然而大多数情况下,并不需要那样的控制,并且可以使用一种嵌入到java语言内部的机制。从Java1.0版开始,Java中的每一个对象都有一个内部锁。如果一个方法用synchronized 关键字声明,那么对象的锁将保护整个方法。也就是说,要调用该方法,线程必须获得内部的对象锁。
内部对象锁只有一个相关条件,wait方法添加到一个线程到等待集中,notifyAll或者notify方法解除等待线程的阻塞状态。也就是说wait相当于调用condition.await(),notifyAll等价于condition.signalAll();
使用synchronized关键字来编写代码要简洁很多,当然要理解这一代码,你必须要了解每一个对象有一个内部锁,并且该锁有一个内部条件。由锁来管理那些试图进入synchronized方法的线程,由条件来管理那些调用wait的线程。
同步代码块
每一个Java对象都有一个锁,线程可以调用同步方法来获得锁,还有另一种机制可以获得锁,通过进入一个同步阻塞,当线程进入如下形式的阻塞: synchronized(obj){
}
同步代码块是非常脆弱的,通常不推荐使用,一般实现同步最好用java.util.concurrent包下提供的类,比如阻塞队列。如果同步方法适合你的程序,那么请尽量的使用同步方法,他可以减少编写代码的数量,减少出错的几率,如果特别需要使用Lock/Condition结构提供的独有特性时,才使用Lock/Condition。
volatile
有时仅仅为了读写一个或者两个实例域就使用同步的话,显得开销过大,volatile关键字为实例域的同步访问提供了免锁的机制。如果声明一个域为 volatile ,那么编译器和虚拟机就知道该域是可能被另一个线程并发更新的。再讲到volatile关键字之前我们需要了解一下内存模型的相关概念以及并发编程中的三个特性:原子性,可见性和有序性
- 原子性,对基本数据类型的变量的读取和赋值操作是原子性操作,即这些操作是不可被中断的,要么执行,要么不执行。
- 可见性,是指线程之间的可见性,一个线程修改的状态对另一个线程是可见的。也就是一个线程修改的结果。另一个线程马上就能看到。
- 有序性,在Java内存模型中,允许编译器和处理器对指令进行重排序,但是重排序过程不会影响到单线程程序的执行,却会影响到多线程并发执行的正确性。
一旦一个共享变量(类的成员变量、类的静态成员变量)被 volatile 修饰之后,那么就具备了两层语义:
- 保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。
- 禁止进行指令重排序。
volatile 不保证原子性但能保证有序性
在满足以下两个条件的情况下,volatile就能保证变量的线程安全问题:
- 运算结果并不依赖变量的当前值,或者能够确保只有单一的线程修改变量的值。
- 变量不需要与其他状态变量共同参与不变约束。
保证操作的原子性就可以使用 volatile ,使用 volatile 主要有两个场景:
- 状态标志
volatile boolean shutdownRequested;
...
public void shutdown()
{
shutdownRequested = true;
}
public void doWork() {
while (!shutdownRequested) {
// do stuff
}
}
- 双重检查模式 (DCL)
public class Singleton {
private volatile static Singleton instance = null;
public static Singleton getInstance() {
if (instance == null) {
synchronized(this) {
if (instance == null) {
instance = new Singleton();
}
}
}
return instance;
}
}
锁的分类

悲观锁、乐观锁
悲观锁认为自己在使用数据的时候一定有别的线程来修改数据,因此在获取数据的时候会先加锁,确保数据不会被别的线程修改。Java 中,synchronized 关键字和 Lock 的实现类都是悲观锁。悲观锁适合写操作多的场景,先加锁可以保证写操作时数据正确。
而乐观锁认为自己在使用数据时不会有别的线程修改数据,所以不会添加锁,只是在更新数据的时候去判断之前有没有别的线程更新了这个数据。如果这个数据没有被更新,当前线程将自己修改的数据成功写入。如果数据已经被其他线程更新,则根据不同的实现方式执行不同的操作(例如报错或者自动重试)。乐观锁在 Java 中是通过使用无锁编程来实现,最常采用的是 CAS 算法,Java 原子类中的递增操作就通过 CAS 自旋实现。乐观锁适合读操作多的场景,不加锁的特点能够使其读操作的性能大幅提升。
自旋锁、适应性自旋锁
阻塞或唤醒一个 Java 线程需要操作系统切换 CPU 状态来完成,这种状态转换需要耗费处理器时间。如果同步代码块中的内容过于简单,状态转换消耗的时间有可能比用户代码执行的时间还要长。
在许多场景中,同步资源的锁定时间很短,为了这一小段时间去切换线程,线程挂起和恢复现场的花费可能会让系统得不偿失。如果物理机器有多个处理器,能够让两个或以上的线程同时并行执行,我们就可以让后面那个请求锁的线程不放弃CPU的执行时间,看看持有锁的线程是否很快就会释放锁。
而为了让当前线程“稍等一下”,我们需让当前线程进行自旋,如果在自旋完成后前面锁定同步资源的线程已经释放了锁,那么当前线程就可以不必阻塞而是直接获取同步资源,从而避免切换线程的开销。这就是自旋锁。
自旋锁本身是有缺点的,它不能代替阻塞。自旋等待虽然避免了线程切换的开销,但它要占用处理器时间。如果锁被占用的时间很短,自旋等待的效果就会非常好。反之,如果锁被占用的时间很长,那么自旋的线程只会白浪费处理器资源。所以,自旋等待的时间必须要有一定的限度,如果自旋超过了限定次数(默认是 10 次,可以使用 -XX:PreBlockSpin 来更改)没有成功获得锁,就应当挂起线程。
自旋锁的实现原理同样也是 CAS,AtomicInteger 中调用 unsafe 进行自增操作的源码中的 do-while 循环就是一个自旋操作,如果修改数值失败则通过循环来执行自旋,直至修改成功。
死锁
当前线程拥有其他线程需要的资源,当前线程等待其他线程已拥有的资源,都不放弃自己拥有的资源。
死锁四大必要条件
- 资源互斥
- 保持与占有
- 不可被剥夺
- 循环等待
阻塞队列
阻塞队列常用于生产者和消费者的场景,生产者是往队列里添加元素的线程,消费者是从队列里拿元素的线程。阻塞队列就是生产者存放元素的容器,而消费者也只从容器里拿元素。
常见阻塞场景
-
当队列中没有数据的情况下,消费者端的所有线程都会被自动阻塞(挂起),直到有数据放入队列。
-
当队列中填满数据的情况下,生产者端的所有线程都会被自动阻塞(挂起),直到队列中有空的位置,线程被自动唤醒。
核心方法
放入数据:
offer(anObject):表示如果可能的话,将anObject加到BlockingQueue里,即如果BlockingQueue可以容纳, 则返回true,否则返回false.(本方法不阻塞当前执行方法的线程)
offer(E o, long timeout, TimeUnit unit),可以设定等待的时间,如果在指定的时间内,还不能往队列中 加入BlockingQueue,则返回失败。
put(anObject):把anObject加到BlockingQueue里,如果BlockQueue没有空间,则调用此方法的线程被阻断直到BlockingQueue里面有空间再继续.
获取数据: poll(time):取走BlockingQueue里排在首位的对象,若不能立即取出,则可以等time参数规定的时间, 取不到时返回null;
poll(long timeout, TimeUnit unit):从BlockingQueue取出一个队首的对象,如果在指定时间内, 队列一旦有数据可取,则立即返回队列中的数据。否则知道时间超时还没有数据可取,返回失败。
take():取走BlockingQueue里排在首位的对象,若BlockingQueue为空,阻断进入等待状态直到 BlockingQueue有新的数据被加入;
drainTo():一次性从BlockingQueue获取所有可用的数据对象(还可以指定获取数据的个数), 通过该方法,可以提升获取数据效率;不需要多次分批加锁或释放锁。
Java中的阻塞队列
JDK7提供了7个阻塞队列,分别是:
-
ArrayBlockingQueue :由数组结构组成的有界阻塞队列。用数组实现的有界阻塞队列。此队列按照先进先出(FIFO)的原则对元素进行排序。
-
LinkedBlockingQueue :由链表结构组成的有界阻塞队列。 基于链表的阻塞队列,同ArrayListBlockingQueue类似,此队列按照先进先出(FIFO)的原则对元素进行排序,其内部也维持着一个数据缓冲队列(该队列由一个链表构成),当生产者往队列中放入一个数据时,队列会从生产者手中获取数据,并缓存在队列内部,而生产者立即返回;只有当队列缓冲区达到最大值缓存容量时(LinkedBlockingQueue可以通过构造函数指定该值),才会阻塞生产者队列,直到消费者从队列中消费掉一份数据,生产者线程会被唤醒,反之对于消费者这端的处理也基于同样的原理。而LinkedBlockingQueue之所以能够高效的处理并发数据,还因为其对于生产者端和消费者端分别采用了独立的锁来控制数据同步,这也意味着在高并发的情况下生产者和消费者可以并行地操作队列中的数据,以此来提高整个队列的并发性能。
-
PriorityBlockingQueue :支持优先级排序的无界阻塞队列。 是一个支持优先级的无界队列。默认情况下元素采取自然顺序升序排列。可以自定义实现compareTo()方法来指定元素进行排序规则,或者初始化PriorityBlockingQueue时,指定构造参数Comparator来对元素进行排序。需要注意哦的是不能保证同优先级元素的顺序。
-
DelayQueue:使用优先级队列实现的无界阻塞队列。 是一个支持延时获取元素的无界阻塞队列。队列使用PriorityQueue来实现。队列中的元素必须实现Delayed接口,在创建元素时可以指定多久才能从队列中获取当前元素。只有在延迟期满时才能从队列中提取元素。我们可以将DelayQueue运用在以下应用场景:
- 缓存系统的设计:可以用DelayQueue保存缓存元素的有效期,使用一个线程循环查询DelayQueue,一旦能从DelayQueue中获取元素时,表示缓存有效期到了。
- 定时任务调度:使用DelayQueue保存当天将会执行的任务和执行时间,一旦从DelayQueue中获取到任务就开始执行,从比如TimerQueue就是使用DelayQueue实现的。
- SynchronousQueue:不存储元素的阻塞队列。
- LinkedTransferQueue:由链表结构组成的无界阻塞队列。
-
LinkedBlockingDeque:由链表结构组成的双向阻塞队列。
实现原理
96 /** The queued items */
97 final Object[] items;
98
99 /** items index for next take, poll, peek or remove */
100 int takeIndex;
101
102 /** items index for next put, offer, or add */
103 int putIndex;
104
105 /** Number of elements in the queue */
106 int count;
107
108 /*
109 * Concurrency control uses the classic two-condition algorithm
110 * found in any textbook.
111 */
112
113 /** Main lock guarding all access */
114 final ReentrantLock lock;
115
116 /** Condition for waiting takes */
117 private final Condition notEmpty;
118
119 /** Condition for waiting puts */
120 private final Condition notFull;
146 /**
147 * Inserts element at current put position, advances, and signals.
148 * Call only when holding lock.
149 */
150 private void enqueue(E x) {
151 // assert lock.getHoldCount() == 1;
152 // assert items[putIndex] == null;
153 final Object[] items = this.items;
154 items[putIndex] = x;
155 if (++putIndex == items.length) putIndex = 0;
156 count++;
157 notEmpty.signal();
158 }
159
160 /**
161 * Extracts element at current take position, advances, and signals.
162 * Call only when holding lock.
163 */
164 private E dequeue() {
165 // assert lock.getHoldCount() == 1;
166 // assert items[takeIndex] != null;
167 final Object[] items = this.items;
168 @SuppressWarnings("unchecked")
169 E x = (E) items[takeIndex];
170 items[takeIndex] = null;
171 if (++takeIndex == items.length) takeIndex = 0;
172 count--;
173 if (itrs != null)
174 itrs.elementDequeued();
175 notFull.signal();
176 return x;
177 }
324 /**
325 * Inserts the specified element at the tail of this queue, waiting
326 * for space to become available if the queue is full.
327 *
328 * @throws InterruptedException {@inheritDoc}
329 * @throws NullPointerException {@inheritDoc}
330 */
331 public void put(E e) throws InterruptedException {
332 Objects.requireNonNull(e);
333 final ReentrantLock lock = this.lock;
334 lock.lockInterruptibly();
335 try {
336 while (count == items.length)
337 notFull.await();
338 enqueue(e);
339 } finally {
340 lock.unlock();
341 }
342 }
382 public E take() throws InterruptedException {
383 final ReentrantLock lock = this.lock;
384 lock.lockInterruptibly();
385 try {
386 while (count == 0)
387 notEmpty.await();
388 return dequeue();
389 } finally {
390 lock.unlock();
391 }
392 }
使用场景
使用阻塞队列put方法和take方法实现生产者-消费者模式无需考虑同步和线程间通信的问题,代码实现简洁很多。
线程池
线程池的优点有以下:
- 重用线程池中的线程,避免因为线程的创建和销毁带来性能开销。
- 能有效控制线程池的最大并发数,避免大量的线程之间因互相抢占系统资源而导致的阻塞现象。
- 能够对线程进行管理,并提供定时执行以及定间隔循环执行等功能。
Java通过Executors提供四种线程池,分别为:
- CachedThreadPool 创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。在线程空闲60秒后终止线程。
- FixedThreadPool 创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
- ScheduledThreadPool 创建一个定长线程池,支持定时及周期性任务执行。
- SingleThreadExecutor 创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
ThreadPoolExecutor是Executor框架的核心实现类,它的构造方法:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
处理流程和原理
处理流程可以查看ThreadPoolExecutor.execute方法:
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
//1.当前池中线程比核心数少,新建一个线程执行任务
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//2.核心池已满,但任务队列未满,添加到队列中
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command)) //如果这时被关闭了,拒绝任务
reject(command);
else if (workerCountOf(recheck) == 0) //如果之前的线程已被销毁完,新建一个线程
addWorker(null, false);
}
//3.核心池已满,队列已满,试着创建一个新线程
else if (!addWorker(command, false))
reject(command); //如果创建新线程失败了,说明线程池被关闭或者线程池完全满了,拒绝任务
//4.达到最大线程数,执行饱和策略,默认抛出RejectedExecutionException异常。
}
线程池的分类
newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
可以看到,FixedThreadPool 的核心线程数和最大线程数都是指定值,也就是说当线程池中的线程数超过核心线程数后,任务都会被放到阻塞队列中。此外 keepAliveTime 为 0,也就是多余的空余线程会被立即终止(由于这里没有多余线程,这个参数也没什么意义了)。
而这里选用的阻塞队列是 LinkedBlockingQueue,使用的是默认容量 Integer.MAX_VALUE,相当于没有上限。
因此这个线程池执行任务的流程如下:
1.线程数少于核心线程数,也就是设置的线程数时,新建线程执行任务
2.线程数等于核心线程数后,将任务加入阻塞队列
3.由于队列容量非常大,可以一直加加加
4.执行完任务的线程反复去队列中取任务执行 FixedThreadPool 用于负载比较重的服务器,为了资源的合理利用,需要限制当前线程数量。 示例代码如下:
package test;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadPoolExecutorTest {
public static void main(String[] args) {
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3);
for (int i = 0; i < 10; i++) {
final int index = i;
fixedThreadPool.execute(new Runnable() {
public void run() {
try {
System.out.println(index);
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
}
因为线程池大小为3,每个任务输出index后sleep 2秒,所以每两秒打印3个数字。定长线程池的大小最好根据系统资源进行设置。如Runtime.getRuntime().availableProcessors()
CachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
CachedThreadPool 没有核心线程,非核心线程数无上限,也就是全部使用外包,但是每个外包空闲的时间只有 60 秒,超过后就会被回收。
CachedThreadPool 使用的队列是 SynchronousQueue,这个队列的作用就是传递任务,并不会保存。
因此当提交任务的速度大于处理任务的速度时,每次提交一个任务,就会创建一个线程。极端情况下会创建过多的线程,耗尽 CPU 和内存资源。
它的执行流程如下:
没有核心线程,直接向 SynchronousQueue 中提交任务
如果有空闲线程,就去取出任务执行;如果没有空闲线程,就新建一个
执行完任务的线程有 60 秒生存时间,如果在这个时间内可以接到新任务,就可以继续活下去,否则就拜拜
由于空闲 60 秒的线程会被终止,长时间保持空闲的 CachedThreadPool 不会占用任何资源。
CachedThreadPool 用于并发执行大量短期的小任务,或者是负载较轻的服务器。
package test;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadPoolExecutorTest {
public static void main(String[] args) {
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
final int index = i;
try {
Thread.sleep(index * 1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
cachedThreadPool.execute(new Runnable() {
public void run() {
System.out.println(index);
}
});
}
}
}
线程池为无限大,当执行第二个任务时第一个任务已经完成,会复用执行第一个任务的线程,而不用每次新建线程。
SingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
从参数可以看出来,SingleThreadExecutor 相当于特殊的 FixedThreadPool,它的执行流程如下:
线程池中没有线程时,新建一个线程执行任务
有一个线程以后,将任务加入阻塞队列,不停加加加
唯一的这一个线程不停地去队列里取任务执行 SingleThreadExecutor 用于串行执行任务的场景,每个任务必须按顺序执行,不需要并发执行。
package test;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class ThreadPoolExecutorTest {
public static void main(String[] args) {
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
for (int i = 0; i < 10; i++) {
final int index = i;
singleThreadExecutor.execute(new Runnable() {
public void run() {
try {
System.out.println(index);
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}
}
结果依次输出,相当于顺序执行各个任务。
ScheduledThreadPool
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) {
return new ScheduledThreadPoolExecutor(corePoolSize);
}
public ScheduledThreadPoolExecutor(int corePoolSize) {
super(corePoolSize, Integer.MAX_VALUE,
DEFAULT_KEEPALIVE_MILLIS, MILLISECONDS,
new DelayedWorkQueue());
}
private static final long DEFAULT_KEEPALIVE_MILLIS = 10L;
ScheduledThreadPoolExecutor 继承自 ThreadPoolExecutor, 最多线程数为 Integer.MAX_VALUE ,使用 DelayedWorkQueue 作为任务队列。ScheduledThreadPoolExecutor 添加任务和执行任务的机制与ThreadPoolExecutor 有所不同。
ScheduledThreadPoolExecutor 添加任务提供了另外两个方法:
scheduleAtFixedRate() :按某种速率周期执行
scheduleWithFixedDelay():在某个延迟后执行
ScheduledThreadPoolExecutor 的执行流程如下:
1. 调用上面两个方法添加一个任务
2. 线程池中的线程从 DelayQueue 中取任务
3. 然后执行任务 具体执行任务的步骤也比较复杂:
线程从 DelayQueue 中获取 time 大于等于当前时间的 ScheduledFutureTask
DelayQueue.take()
执行完后修改这个 task 的 time 为下次被执行的时间
然后再把这个 task 放回队列中
DelayQueue.add()
ScheduledThreadPoolExecutor 用于需要多个后台线程执行周期任务,同时需要限制线程数量的场景。
package test;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class ThreadPoolExecutorTest {
public static void main(String[] args) {
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(5);
scheduledThreadPool.schedule(new Runnable() {
public void run() {
System.out.println("delay 3 seconds");
}
}, 3, TimeUnit.SECONDS);// 延迟3秒执行
}
}
package test;
import java.util.concurrent.Executors;
import java.util.concurrent.ScheduledExecutorService;
import java.util.concurrent.TimeUnit;
public class ThreadPoolExecutorTest {
public static void main(String[] args) {
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(5);
scheduledThreadPool.scheduleAtFixedRate(new Runnable() {
public void run() {
System.out.println("delay 1 seconds, and excute every 3 seconds");
}
}, 1, 3, TimeUnit.SECONDS);// 延迟1秒后每3秒执行一次
}
}
AsyncTask的原理
AsyncTask 封装了 Thread 和 Handler,并不适合特别耗时的后台任务,对于特别耗时的任务来说,建议使用线程池。
基本使用
| 方法 | 说明 | | ——————————- | ———————————————————— | | onPreExecute() | 异步任务执行前调用,用于做一些准备工作 | | doInBackground(Params…params) | 用于执行异步任务,此方法中可以通过 publishProgress 方法来更新任务的进度,publishProgress 会调用 onProgressUpdate 方法 | | onProgressUpdate | 在主线程中执行,后台任务的执行进度发生改变时调用 | | onPostExecute | 在主线程中执行,在异步任务执行之后 |
import android.os.AsyncTask;
public class DownloadTask extends AsyncTask<String, Integer, Boolean> {
@Override
protected void onPreExecute() {
super.onPreExecute();
}
@Override
protected Boolean doInBackground(String... strings) {
return null;
}
@Override
protected void onProgressUpdate(Integer... values) {
super.onProgressUpdate(values);
}
@Override
protected void onPostExecute(Boolean aBoolean) {
super.onPostExecute(aBoolean);
}
}
- 异步任务的实例必须在 UI 线程中创建,即 AsyncTask 对象必须在UI线程中创建。
- execute(Params… params)方法必须在UI线程中调用。
- 不要手动调用 onPreExecute(),doInBackground(),onProgressUpdate(),onPostExecute() 这几个方法。
- 不能在 doInBackground() 中更改UI组件的信息。
- 一个任务实例只能执行一次,如果执行第二次将会抛出异常。
- execute() 方法会让同一个进程中的 AsyncTask 串行执行,如果需要并行,可以调用 executeOnExcutor 方法。
源码分析
Android3.0之前的AsyncTask没必要学习,但可知它的线程池最大的线程数是128,较少,缺点明显。
主要分析Android7.0的AsyncTask
AsyncTask.java
@MainThread
public final AsyncTask<Params, Progress, Result> execute(Params... params) {
return executeOnExecutor(sDefaultExecutor, params);
}
@MainThread
public final AsyncTask<Params, Progress, Result> executeOnExecutor(Executor exec,
Params... params) {
if (mStatus != Status.PENDING) {
switch (mStatus) {
case RUNNING:
throw new IllegalStateException("Cannot execute task:"
+ " the task is already running.");
case FINISHED:
throw new IllegalStateException("Cannot execute task:"
+ " the task has already been executed "
+ "(a task can be executed only once)");
}
}
mStatus = Status.RUNNING;
onPreExecute();
mWorker.mParams = params;
exec.execute(mFuture);
return this;
}
sDefaultExecutor 是一个串行的线程池,一个进程中的所有的 AsyncTask 全部在该线程池中执行。AysncTask 中有两个线程池(SerialExecutor 和 THREAD_POOL_EXECUTOR )和一个 Handler( InternalHandler ),其中线程池 SerialExecutor 用于任务的排队,THREAD_POOL_EXECUTOR 用于真正地执行任务,InternalHandler 用于将执行环境从线程池切换到主线程。
AsyncTask.java
private static Handler getMainHandler() {
synchronized (AsyncTask.class) {
if (sHandler == null) {
sHandler = new InternalHandler(Looper.getMainLooper());
}
return sHandler;
}
}
private static class InternalHandler extends Handler {
public InternalHandler(Looper looper) {
super(looper);
}
@SuppressWarnings({"unchecked", "RawUseOfParameterizedType"})
@Override
public void handleMessage(Message msg) {
AsyncTaskResult<?> result = (AsyncTaskResult<?>) msg.obj;
switch (msg.what) {
case MESSAGE_POST_RESULT:
// There is only one result
result.mTask.finish(result.mData[0]);
break;
case MESSAGE_POST_PROGRESS:
result.mTask.onProgressUpdate(result.mData);
break;
}
}
}
private Result postResult(Result result) {
@SuppressWarnings("unchecked")
Message message = getHandler().obtainMessage(MESSAGE_POST_RESULT,
new AsyncTaskResult<Result>(this, result));
message.sendToTarget();
return result;
}
HandlerThread
HandlerThread 集成了 Thread,却和普通的 Thread 有显著的不同。普通的 Thread 主要用于在 run 方法中执行一个耗时任务,而 HandlerThread 在内部创建了消息队列,外界需要通过 Handler 的消息方式通知 HanderThread 执行一个具体的任务。
HandlerThread.java
@Override
public void run() {
mTid = Process.myTid();
Looper.prepare();
synchronized (this) {
mLooper = Looper.myLooper();
notifyAll();
}
Process.setThreadPriority(mPriority);
onLooperPrepared();
Looper.loop();
mTid = -1;
}
IntentService
IntentService 可用于执行后台耗时的任务,当任务执行后会自动停止,由于其是 Service 的原因,它的优先级比单纯的线程要高,所以 IntentService 适合执行一些高优先级的后台任务。在实现上,IntentService 封装了 HandlerThread 和 Handler 。
IntentService.java
@Override
public void onCreate() {
// TODO: It would be nice to have an option to hold a partial wakelock
// during processing, and to have a static startService(Context, Intent)
// method that would launch the service & hand off a wakelock.
super.onCreate();
HandlerThread thread = new HandlerThread("IntentService[" + mName + "]");
thread.start();
mServiceLooper = thread.getLooper();
mServiceHandler = new ServiceHandler(mServiceLooper);
}
IntentService 第一次启动时,会在 onCreatea 方法中创建一个 HandlerThread,然后使用的 Looper 来构造一个 Handler 对象 mServiceHandler,这样通过 mServiceHandler 发送的消息最终都会在 HandlerThread 中执行。每次启动 IntentService,它的 onStartCommand 方法就会调用一次,onStartCommand 中处理每个后台任务的 Intent,onStartCommand 调用了 onStart 方法:
IntentService.java
private final class ServiceHandler extends Handler {
public ServiceHandler(Looper looper) {
super(looper);
}
@Override
public void handleMessage(Message msg) {
onHandleIntent((Intent)msg.obj);
stopSelf(msg.arg1);
}
}
···
@Override
public void onStart(@Nullable Intent intent, int startId) {
Message msg = mServiceHandler.obtainMessage();
msg.arg1 = startId;
msg.obj = intent;
mServiceHandler.sendMessage(msg);
}
可以看出,IntentService 仅仅是通过 mServiceHandler 发送了一个消息,这个消息会在 HandlerThread 中被处理。mServiceHandler 收到消息后,会将 Intent 对象传递给 onHandlerIntent 方法中处理,执行结束后,通过 stopSelf (int startId) 来尝试停止服务。(stopSelf () 会立即停止服务,而 stopSelf (int startId) 则会等待所有的消息都处理完毕后才终止服务)。